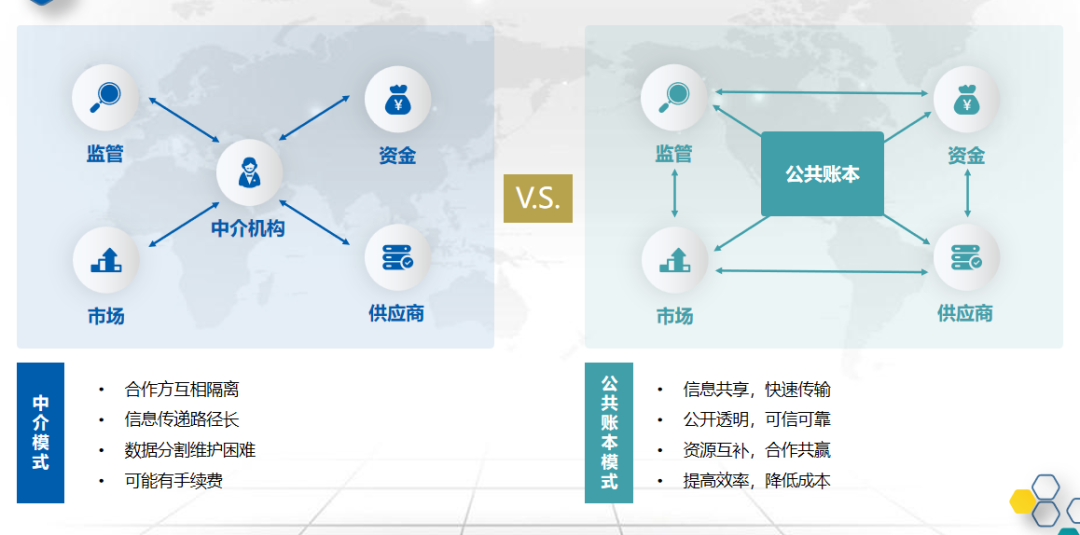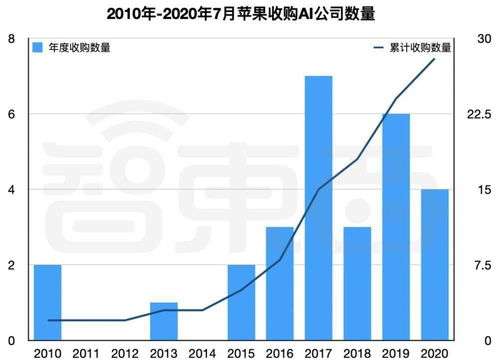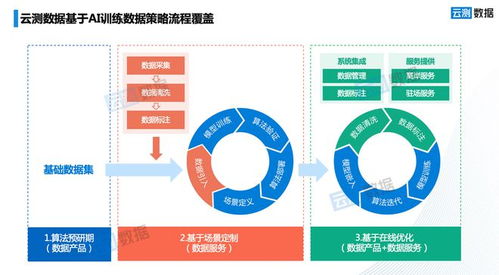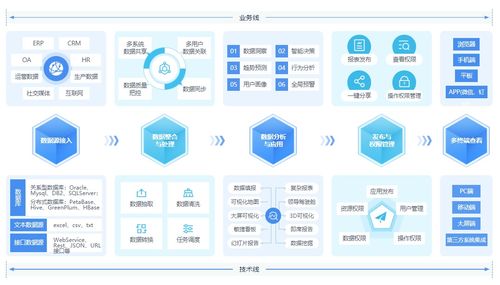
在当今企业数字化转型的浪潮中,数据已成为驱动决策、优化运营与创新业务的核心资产。如何高效、可靠且经济地管理海量、多元的实时与历史数据,是每个组织面临的关键挑战。传统的“数据仓库”与“数据湖”架构各有优势与局限,而融合二者所长的“湖仓一体化”架构,正演进为现代企业数据底座的基石,并催生出新一代的、强大的数据处理服务。
一、数据底座:数字化转型的稳固基石
数据底座,是企业数据能力的集中体现,它并非单一的技术产品,而是一个融合了数据存储、计算、管理、治理与服务化的综合性平台。一个坚实的数据底座具备以下特征:高弹性可扩展,以应对数据量的爆炸式增长;多模数据支持,能够处理结构化、半结构化和非结构化数据;统一治理与安全,确保数据在流动中的质量、合规与安全;以及开放与敏捷,能够快速响应业务变化,支持多样化的分析与应用需求。它是实现数据资产化、服务化的前提,是上层数据分析、人工智能应用和业务创新的基础支撑。
二、从分立到融合:湖仓一体化的演进之路
过去,数据仓库擅长处理高度结构化的业务数据,支持复杂的交互式分析与报表,但 schema 先于数据写入的约束使其难以应对原始、多样、快速变化的数据。数据湖则以低成本存储原始数据(任何格式),具有极高的灵活性,但常因缺乏有效治理而沦为“数据沼泽”,难以保障数据的质量和分析的性能。
“湖仓一体化”架构应运而生,它旨在打破湖与仓之间的壁垒,构建一个统一的数据管理范式。其核心思想是:
- 统一存储层:通常基于低成本、高可靠的对象存储(如云上的S3、OSS等),同时保存原始数据与处理后的精炼数据,实现数据不移动。
- 融合计算引擎:支持在统一的数据存储之上,运行多种计算框架,包括用于大数据处理的批处理引擎(如Spark)、用于实时分析的流处理引擎(如Flink),以及高性能的交互式SQL查询引擎(如Presto/Trino,以及数据仓库自身的MPP引擎)。
- 分层数据管理与治理:在统一的架构下,实现数据从原始层、明细层、汇总层到应用层的流畅流转与生命周期管理,并施加统一的元数据管理、数据血缘、质量控制和权限体系。
湖仓一体化并非简单的技术堆叠,而是通过如Delta Lake、Apache Iceberg、Apache Hudi等开放数据表格式实现的架构革新。这些格式为存储在数据湖中的大规模数据集带来了ACID事务、模式演进、时间旅行等数据仓库级的管理能力,从而在保持数据湖灵活性与成本优势的获得了数据仓库的可靠性、性能与治理便利。
三、赋能业务:基于湖仓一体的数据处理服务
以湖仓一体化架构为基石,数据处理服务得以升级为更高效、更智能、更易用的形态。这种服务化体现在:
- 批流一体的数据处理管道:服务能够无缝处理实时流数据与历史批数据,实现真正的实时分析与决策。例如,用户行为点击流可以实时入湖并立即参与风控模型的更新,同时与历史订单批数据关联进行长期趋势分析。
- 自助式数据分析与探索:通过统一的数据目录和元数据服务,业务分析师和数据科学家能够像在数据仓库中一样,轻松地发现、理解和查询存储在湖中的海量数据,进行自助分析、机器学习建模,而无需深陷数据搬运和格式转换的泥潭。
- AI与数据智能的天然土壤:湖仓一体架构存储了最丰富、最原始的数据,为机器学习提供了充足的“养料”。数据处理服务可以紧密集成MLOps流程,从数据准备、特征工程到模型训练与部署,形成高效闭环。
- 云原生与弹性服务:现代湖仓一体方案普遍构建在云基础设施之上,数据处理服务能够按需弹性伸缩计算与存储资源,实现极致的成本优化和运维自动化,企业可按使用量付费,专注于数据价值本身。
- 数据产品与API化输出:经过处理、加工后的高质量数据,可以通过标准API、数据服务层或数据市场的方式,安全、可控地提供给内部各业务部门或外部合作伙伴消费,直接驱动前端应用,实现数据价值的最大化释放。
在数字化转型的深水区,构建以湖仓一体为核心的数据底座,并在此基础上发展出敏捷、智能、全栈的数据处理服务,已成为企业的必然选择。它不仅仅是一次技术架构的升级,更是一种数据管理理念和运营模式的变革。通过将数据的存储、处理、治理与应用深度融合,企业能够打破数据孤岛,提升数据流转效率,降低总体拥有成本,最终构建起面向未来的数据驱动能力,在激烈的市场竞争中赢得先机。从“拥有数据”到“敏捷用数”,湖仓一体化及其支撑的数据处理服务,正引领我们驶向智能数据时代的新蓝海。